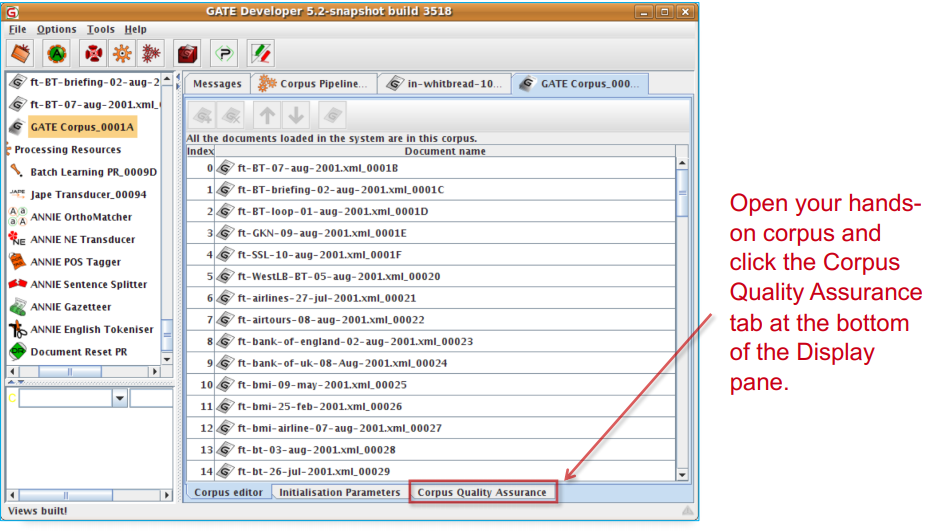
Corpus Quality Assurance¶
• Corpus Quality Assurance tool extends the Annotation
Diff functionality to the entire corpus, rather than on a single
document at a time.
• It produces statistics both for the corpus as a whole
(Corpus statistics tab) and for each document separately
(Document statistics tab).
• It compares two annotation sets, but makes no
assumptions about which (if either) set is the gold
standard. It just labels them A and B.
• This is because it can be used to measure Inter Annotator
Agreement (IAA) where there is no concept of “correct” set.
Try out Corpus Quality Assurance¶
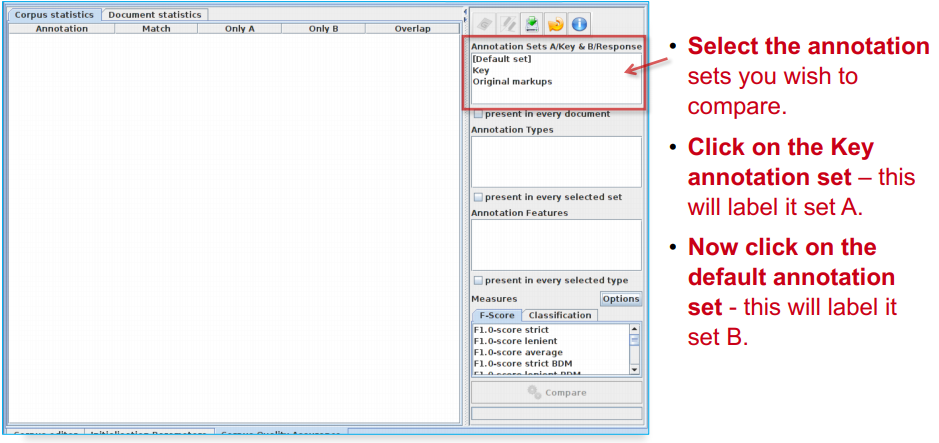
Select Annotation Sets¶
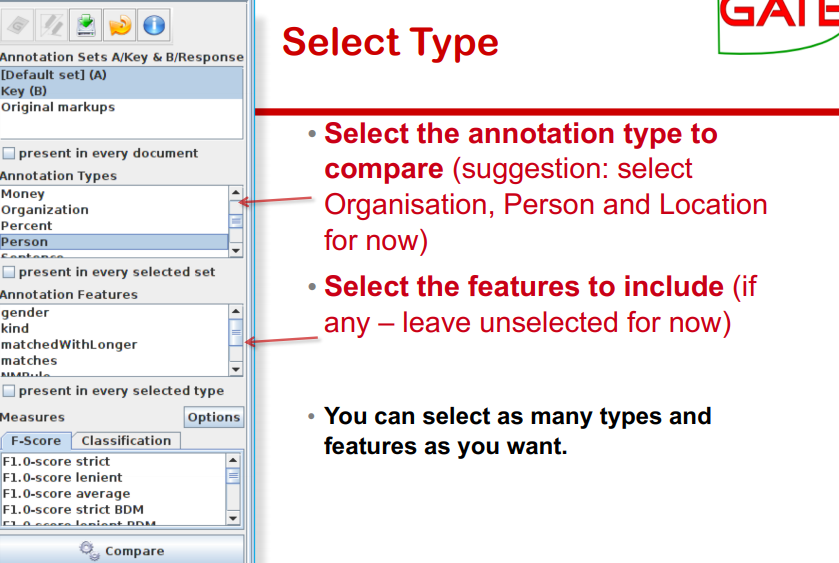
Select Type¶
Corpus Statistics Tab¶
• Each annotation type is listed separately
• Precision, recall and F measure are given for each
• Two summary rows provide micro and macro averages

Micro and Macro Averaging¶
• Micro averaging treats the entire corpus as one big
document, for the purposes of calculating precision,
recall and F.
• Macro averaging takes the average of the rows.
Here: the average over different annotation types
Document Statistics Tab¶
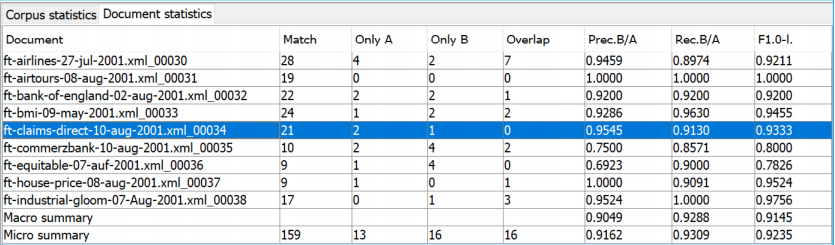
• Each document is listed separately.
• Precision, recall and F-measure are given for each.
• Two summary rows provide micro and macro (here: over
documents) averages.
• By default, Corpus Quality
Assurance presents the Fmeasures.
• However, classification
measures are also available.
• These are not suitable for
entity extraction tasks.